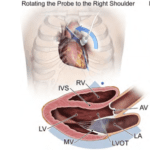
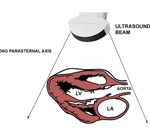
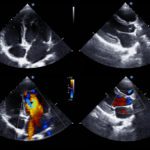
Verify Certification Status Login | Register
Your data is split into partitions and processed in parallel.
Build scalable machine learning pipelines using built-in algorithms. 💡 Pro-Tip: Pandas API on Spark
Process petabytes that crash standard Pandas.